Allons plus loin dans le détail.
Reprenons notre technique de "filtre magique" que je vais appliquer sur ma pomme. Je prend une image référence d'un buste en céramique ainsi qu'une image référence pour la posture qui sera utilisée à la fois pour placer la position des yeux, nez, bouche sur l'image ainsi qu'un contrôleur de niveau de profondeur. Le fait que l'image de référence pour la position du buste soit une femme alors que le rendu doit être un homme n'a ici aucune importance. Enfin j'ajoute une photo du sujet (moi) pour servir de référence au contrôleur InstantID en charge de maintenir une cohérence des traits du visage.


Cette fois-ci on y ajoute une étape supplémentaire dite "d'upscale d'image" en bon franglais c'est-à-dire qu'on augmente la définition de l'image en essayant de créer du détail avec des modèles particuliers, entrainés à cette tâche. Il existe une offre pléthorique dans le domaine le plus souvent à base de solution payante et / ou sur serveur distant. L'idée ici est de ne pas payer un radis ainsi que de ne pas envoyer ses documents et données personnelles à des tiers pas forcement dignes de confiance. Heureusement il existe de quoi faire en local (et pas qu'un peu). Un des soucis de l'upscale est que les modèles ont besoin de se sentir à l'aise dans la mémoire vidéo en prenant un maximum de place et de ce fait peuvent mettre à genoux les machines qui ont la mauvaise idée de ne pas coûter 6000 €. On va donc recourir à une technique qui consiste à découper l'image en morceaux ou "tiles" (tuiles) et les traiter indépendamment, ce qui économisera la mémoire vidéo. On obtient comme on le voit dans l'exemple, une amélioration spectaculaire du rendu avec l'ajout de détails.
A ce stade mon édifice d'application de "filtre" commence à devenir bien conséquent et monopolise pas mal de modèles différents. On va revenir un instant sur ce mille-feuilles pour comprendre sans trop rentrer dans le détail comment tout cela s'articule.
Comment ça marche tout ça ?
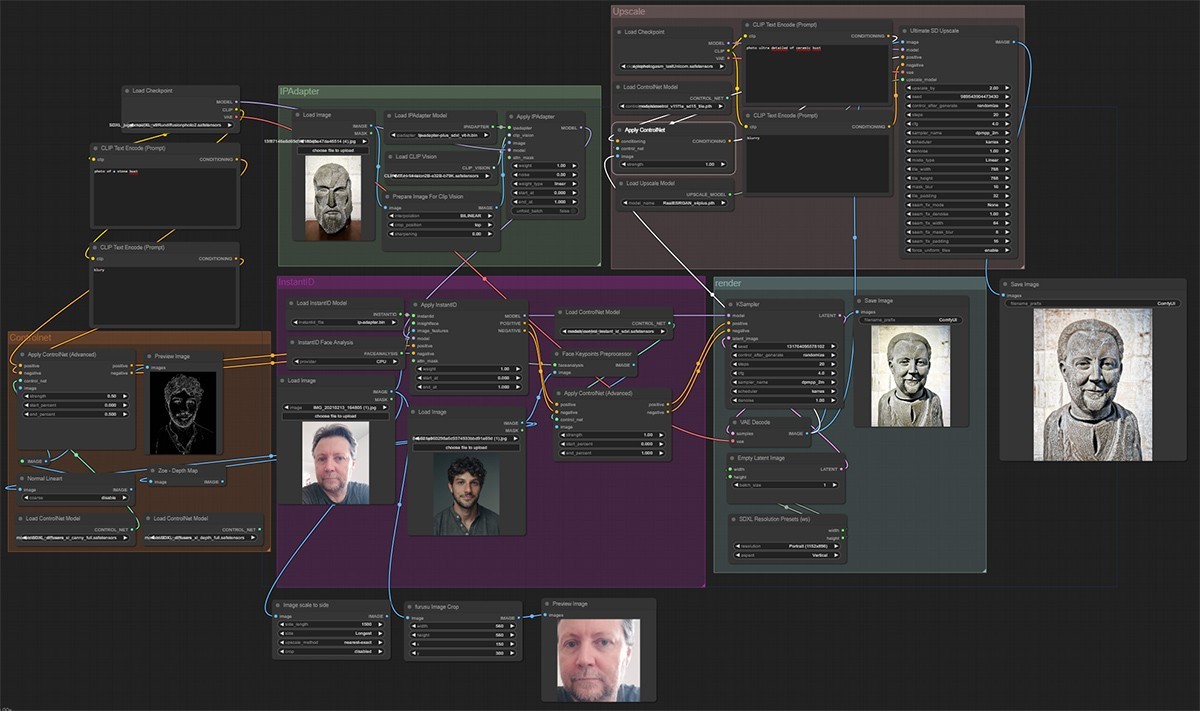
Je vais tenté d'expliquer en m'appuyant sur la lecture des différentes documentations et littératures sur tous les processus en œuvre ici. Je ne suis pas à l'abri de dire de grosses conneries même si je vais de toute façon simplifier beaucoup. Il va de soi que vous pouvez passer ce passage sans que votre vie en soit perturbée. L'inverse est moins sûr.
On commence par charger le modèle de base ou checkpoint qui sera chargée de générer l'image finale, ce qui n'est pas rien. Ici je prends Juggernaut XL qui est un modèle assez versatile basé sur SDXL. On peut prendre évidement ce que l'on veut. On choisit aussi une image référence qui sera "l'inspiration" générale du résultat. Cette image va être analysée avec l'aide d'un modèle appelé ClipVision dont le but est de traduire l'image en "token", des "instructions" compréhensibles par les modèles. Associés à un autre modèle appelé IPAdapter ils vont surcharger le modèle de base pour prendre en compte les éléments constitutifs de l'image référence. En parallèle on a un prompt (2 en réalité, un positif et un négatif mais ne compliquons pas) c'est-à-dire du texte décrivant le résultat attendu. Ce texte de la même manière que pour l'image est transformé en instructions grâce à CLIP (sans vision) qui, lui, est intégré au modèle de base. Ce prompt "traduit" en condition pour la machine va être à son tour surchargé par un ou plusieurs contrôleurs (dans notre cas je n'en utilise qu'un) qui, sur la base d'une nouvelle image référence, que l'on va appeler "image référence de position du personnage", ajoute des informations de profondeur ou de contour selon le model de contrôleur utilisé. Tout ce bazar rejoint le modèle surchargé précédemment pour se faire à nouveau modifier par un modèle spécialiste des visages qui va tirer des informations d'une 3ème image référence (ma poire, en l'occurrence). Le prompt passera une dernière fois dans les griffes d'un contrôleur avec un modèle qui, sur la base de notre référence de position du personnage, en précisera les points clés du visage.
Enfin tout ce beau monde se retrouve dans un sampler, dont je vais passer les détails, pour le moment tant attendu du rendu.
L'image ainsi créée est envoyée au module d'upscale. Ici le contrôleur en charge de découper l'image en tuiles n'est disponible que pour des modèles SD1.5 (en tout cas je n'en ai pas trouvé pour SDXL). Qu'à cela ne tienne, je charge donc un nouveau modèle 1.5 ainsi que le modèle du contrôleur de tuiles. Un nouveau prompt est défini pour permettre un meilleur contrôle de l'ajout de détails et zou, direction l'upscaler, non sans avoir chargé le modèle d'upscale (le 9eme ?) pour enfin le dernier rendu.
Voici enfin quelques exemples avec différentes images références.





